
- PDF:PDF版をダウンロード
- DOI: https://doi.org/10.15108/stih.00393
- 公開日: 2025.03.21
- 著者: 科学技術・学術政策研究所 企画課
- 雑誌情報: STI Horizon, Vol.11, No.1
- 発行者: 文部科学省科学技術・学術政策研究所 (NISTEP)
ナイスステップな研究者2023講演会
講演会「近未来への招待状~ナイスステップな研究者
2023からのメッセージ~」第3回
科学技術・学術政策研究所(NISTEP)では毎年、科学技術イノベーションの様々な分野において活躍され、日本に元気を与えてくれる方々を「ナイスステップな研究者」として選定している。選定された10名のうち、3名の方々に第3回講演会として2024年7月23日(火)に自らの研究活動やキャリアパスについて御講演いただいた。本記事では、それぞれの御講演内容に沿って要旨とポイントを記載している。
キーワード:ナイスステップな研究者
講演タイトル:視覚と言葉を繋ぐAIのこれまでとこれから

Vice President for Research 牛久 祥孝 氏
(牛久氏提供)
知能機械情報学専攻博士課程 修了 博士
(情報理工学)
2014年 日本電信電話株式会社
コミュニケーション科学基礎研究所 研究員
2016年 東京大学 大学院情報理工学系研究科
知能機械情報学専攻 講師
2018年 オムロンサイニックエックス株式会社
Principal Investigator
2019年 株式会社Ridge-i Chief Research Officer(兼務)
2024年 オムロンサイニックエックス株式会社
Vice President for Research
講演要旨:
2010年代から第3次AIブームが起き、人々の生活の裏でもいろいろなAIが活躍するようになってきた。その中で、人の視覚(画像や動画)と言葉(テキスト)を結び付けて理解したり生成したりするAIの研究と応用も進んでいる。本講演では、こうした視覚と言葉をつなぐAIである Vision and Language と呼ばれる研究分野について話す。AIとは何か、特に最近話題の生成AIとは何か、それまでのAIとは違うものなのかどうかということについて簡単に触れつつ、視覚と言葉をつなぐ Vision and Language の代表例を紹介する。また最後に、こうした Vision and Language の応用として、観測されるデータ(実験データ)とテキスト(論文などの科学的知識)を結び付けることによってAIロボット自体が研究を加速する、AIロボット駆動科学の取組についても言及する。
講演のポイント:
AI研究において3つの非常にセンセーショナルな事件が起きた年を紹介します。2011年には音声認識技術の精度が劇的に向上し、エラー率が10ポイントも改善しました。2012年には画像認識技術が飛躍し、認識精度が大幅に向上。2014年にはシンプルなモデルでも高精度な翻訳が可能となり、機械翻訳が進化しました。これらはすべて深層学習、いわゆるディープラーニング技術によるもので、第3次AIブームを引き起こしました。その後、2022年以降には生成AIが普及し、ChatGPTやStable Diffusionといった技術が社会的に認知を集めました。これにより、第4次AIブームになったと言う方もいます。
こういった音声・画像・テキストを理解する「理解のAI」というものが進化してきたのですが、単純化すれば2つのタスクで回っています。1つは「識別」で、例えば脳の画像からどこが海馬かを判定するのであれば、画素ごとにこれは海馬だな、これは海馬でないなと色塗りをするように、離散値での推定を行うもの。もう1つは「回帰」で、例えば脳の画像から体積がどれくらいかを見積もるなど、連続的な値のどこら辺かを推定するものです。
深層学習が発見される前は、画像認識、機械翻訳などでいろいろ異なる技術を順次適用して結果を得ており、それぞれの研究者間で何をやっているのか分からないというような状況でした。しかし、深層学習というのは人間の脳細胞神経にインスパイアされた技術で、画像認識でも機械翻訳でも使う技術がほぼ同じになります。これが深層学習によって起きた一つの大きな変化です。そして同時期に起きたもう一つの変化が、大量の動画やテキストのペアが収集できるようになったことで、Vision and Languageという画像とテキストを融合するような研究が増え始めたことでした。その例を3つ紹介します。
1つ目の「ビジュアル質問応答」では、画像を入力し、質問を与えるとAIが適切な回答を生成します。2つ目は、画像が入ってきたときに、その内容をテキストで説明する「画像キャプション生成」です。3つ目が、逆にテキストから画像が生成できるのでは、ということで、「キャプションからの画像生成」です。例えば「ハリネズミの魔法使いが車を運転している絵」といったユニークなリクエストに応じてAIが画像を生成することができます(図表1)。
最近のChatGPTといったアプリは、Vision and Languageのいろいろなことができるようになったものだ、と言うこともできます。一見新しい技術のようですが、その根本は従来のAIと同じです。例えば画像キャプション生成では、数万のボキャブラリから画像にふさわしい1単語目を推定し、更に2単語目を推定していきます。これは正に「識別」です。逆に、キャプションからの画像生成では、各画素のRGBはどういう値かを「回帰」します。
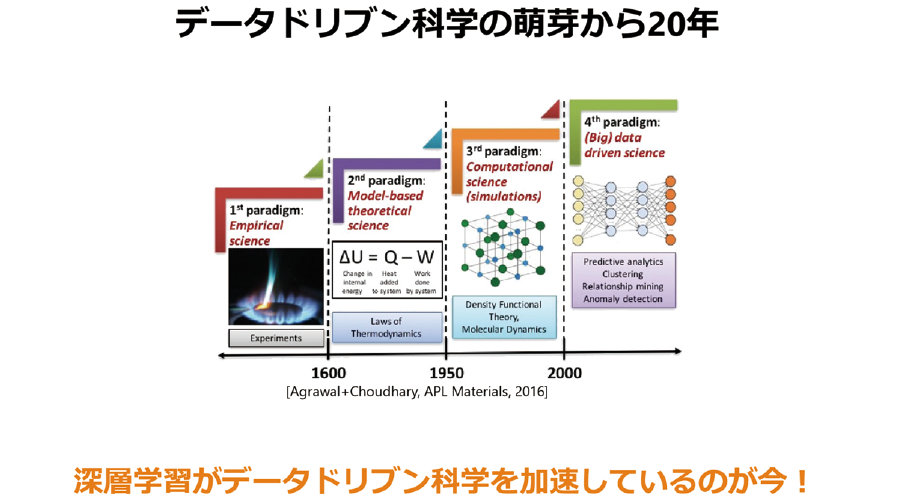
最後に、AIロボット駆動科学の話です。科学はいろいろな形態に進化してきており、今は第4世代と呼ばれています。この金属を燃やすとこの色になるぞといった経験的な科学、数式的にそういう現象を説明しようという方程式の科学、計算機を使ってのシミュレーションといった演繹的にデータを扱う科学、そして帰納的にデータを使っていくデータドリブン科学と進化していったのですが、このデータドリブン科学が更にAIによって加速し、AIドリブン科学みたいなものが出てきています(図表2)。
例えば、大量のデータから科学法則を発見するとか、実験のような複雑な作業をロボットにやらせるとか。そういうところに需要が生まれてきていまして、私自身も科学技術振興機構(JST)からの委託研究で、AIロボットにノーベル賞を受賞させるようなAIロボットサイエンティストを作ろうという取組を行っています。
今後も、視覚や言葉、いろいろなデータを超えてつないでいきながら、より人間の創造的な活動をサポートできるような研究を進めていきたいと考えております。

講演タイトル:古代の智慧×最先端テクノロジーでイノベーションを創発

熊谷 誠慈 氏(熊谷氏提供)
博士(文学)
2009年 日本学術振興会特別研究員PD
2011年 京都大学 白眉センター 特定助教
2012年 京都大学 こころの未来研究センター
特任准教授
2018年 ウィーン大学 文献文化学部 特任教授(兼任)
2021年 内閣府ムーンショット型研究開発制度(目標9)
プログラムディレクター(PD)
2022年 株式会社テラバース 共同創業者
2023年 京都大学 人と社会の未来研究院 教授
講演要旨:
私は、インドやチベット等の古代文書の解読を通じて伝統知(伝統的な知識や知恵)を回収し、それらとテクノロジーを融合した「伝統知テック」の開発を進めるなど、「産・宗・学連携」による「総合知」を用いた研究開発を推進してきた。本講演では、その開発事例を紹介する。
私の研究開発グループは、2021年3月、人工知能に最古の仏教経典『スッタニパータ』を機械学習させた仏教対話AI「ブッダボット」を開発、公表した。その2年後の2023年7月には、上記対話AIにChatGPTの最新版(公開当初はChatGPT4)を統合した「ブッダボットプラス」を開発し、より具体的かつ詳細な回答や解説を可能とした。同9月には、「親鸞ボット」と「世親ボット」を開発し、ボットの複数化・多様化を実現した。
また、テキスト対話だけにとどまらず、AR(拡張現実技術)を用いて、「テラ・プラットフォームAR Ver1.0」を開発し、視覚・聴覚・触覚を用いた多感覚伝統知コミュニケーションを実現した。
これまで、AIに仏教のデータのみを学習させてきたが、今後、さらに仏教以外のデータを学習させていくことで、多数のサイバー・フィジカル融合世界の構築が可能となる。最終的には「一兆の宇宙」(テラバース)の構築を目指し、開発を推進している。
これらの総合知や技術を応用することで、新たな思想、文化、芸術などの創出可能性がある。また、これらを産業界にも応用し、実業家の古屋俊和氏と株式会社テラバースを共同創業するなど、「伝統知テック産業」の開拓を進めている。
講演のポイント:
私は仏教学を専門とする研究者で、古文書を解析し、サンスクリット語や古典チベット語などを用いて仏教の思想を解明するといったことを主な仕事としています。歴史書を基に遺跡を探すこともあり、例えばブータン仏教の開祖ツァンパギャレーの生誕地を世界で初めて発見しました。しかしながら、当時の私の研究は役に立たないと言われることも多く、また、文書に書かれている文字情報では机上の空論になってしまうのではないかと悩んでいました。
そんな中、2011年のブータン国王の来日が大きな注目を集めました。すると、瞬く間に私の「役に立たない研究」が、「すばらしい研究」だと言われるようになりました。研究の社会的評価というのは絶対的でなく、時流に左右されやすいものだと気付きました。
そして、ブータンの仏教哲学を基に、新しい幸福哲学を展開していきました。行政の方々は興味を持ってくれるのですが、実際に政策に反映されて国民に利益として届くのは極めて難しく、行動するにしても何をやって良いか分からないといった悩みの中過ごしておりましたが、ある日転機が訪れます。
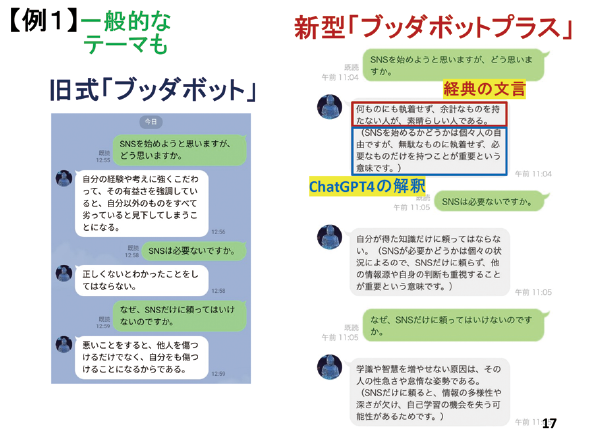
仏教界からの要請で、衰退気味の仏教を復興できないかということで、議論する機会があり、その中でAIと仏教を組み合わせるアイデアが生まれました。そしてできあがったのが、非生成系のAI仏教チャットボット「ブッダボット」です。その後、高性能な生成系AIであるChatGPT3.5が登場したことを受けて、非生成系の旧式ブッダボットと生成系のChatGPT4を融合した生成系仏教対話AI「ブッダボットプラス」も公表しました。
例えば、旧式ブッダボットが「SNSを始めるべきか」といった質問に対して、経典から近いと思われる情報を出力します。「何ものにも執着せず、余計なものを持たない人が、素晴らしい人である」と出ますが、これだけではピンと来ない。それに対してChatGPT4が回答を補足します。「SNSを始めるかどうかは個々人の自由ですが~」と(図表3)。
こうした生成系AIを統合したことで非常に性能は上がったのですが、むしろ不安を持ったという方々もいました。ゴーダマ・シッダールタという一人の思想をAIでばらまいてしまうと、画一的な思想統制がなされてしまうのではないかと。そこで、多様な思想を反映させるため、「親鸞ボット」や「世親ボット」といった複数の新しいチャットボットも開発しました。
また、テキスト対応だけでは物足りないということもあり、顔を見て声を聞いて意思疎通がしたいと思い、チャットボット×ARといったプロダクトも開発しました。あとは、こういった技術を用いて、新しいサイバー・フィジカル・システムを構築しようということで、「テラバース」(一兆の宇宙)を創るという構想を発表したのが2022年9月のことです。
背景としては、2040年には3割のお寺が廃寺になるとも言われていまして、お寺をインターネットでつないで、現実空間上の寺院の経営を安定化させるとか、VRを利用して仮想空間上にお寺や極楽浄土を作ってみようとか、そういったことにチャレンジしようとしました。ですが、VRはいわゆる不気味の谷という現象もありましてまだ難しいということで、今はARに舵を切っているところです。
社会や文化、産業への波及効果という点で言うと、伝統知とテクノロジーの融合により、物理空間の障害を越え、圧迫感や生きづらさを解消できる可能性があります。もちろん、悪用や誤用のリスクもありますが、新しいものを創出できる可能性は大いにあると思います(図表4)。
こういったコンセプトを作り、伝統知テック産業として産業界にも呼び掛けようとしたのですが、市場規模が0円のところにリスクを冒して参入するというのも企業側にとっては難しいということで、まず我々が株式会社テラバースというスタートアップを創業しまして、取りあえず市場を0円から1円以上にしたところです。
異分野融合で0を1に変える研究開発ができたのは、多様な考えを持った仲間たちとの協働のおかげでもあり、役に立たないと言われがちのものでも場合によっては新しい価値やプロダクトを生み出す可能性があります。本日の議論を通じて、新しい創発が出てくることを願っております。

講演タイトル:大規模言語モデルのこれまでとこれから

秋葉 拓哉 氏(秋葉氏提供)
2015年 東京大学 大学院 情報理工学系研究科
コンピュータ科学専攻博士課程 修了
2015年 国立情報学研究所 特任助教
2016年 株式会社Preferred Networks リサーチャー
2018年 株式会社Preferred Networks 執行役員
機械学習基盤担当VP
2023年 Stability AI Japan株式会社
Senior Research Scientist
講演要旨:
進化的アルゴリズムを用いて多様なオープンソースモデルを融合することで新しい基盤モデルを効率的に開発する手法「進化的モデルマージ」を提案する。我々のアプローチは、既存のオープンモデルの膨大な集合知を活用するため、モデルを非常に効率的に作成できる。進化的モデルマージは、「非英語言語と数学的推論」「非英語言語と画像」といった、これまでは困難と思われていた全く異なる領域のモデルをマージする方法すらも自動的に発見できることが分かった。
講演のポイント:
本日は大規模言語モデルのこれまでとこれからについて、特に「進化的モデルマージ」という新しい技術を中心にお話しさせていただきます。進化的モデルマージは、既存のオープンソースモデルを融合し、新しい基盤モデルを効率的に開発する手法です。
まず、Sakana AIという我々の会社について簡単に御紹介いたします。当社は2023年7月に設立され、日本を拠点に活動しています。共同創設者のDavid HaはGoogle Brain Tokyoのリーダーを務めた機械学習・進化計算の専門家であり、Llion Jonesはトランスフォーマー技術の開発に関わった研究者です。我々は、ファンデーションモデルと呼ばれる最先端のAI研究について、自然から着想を得たアイデアを使って、改善や新しいアプローチへの挑戦を目指しています。
現在の大規模言語モデルは、大規模なリソースを投入し、長期間にわたりモデルを学習させています。これにより便利なAIが開発されてきましたが、多大な計算資源と時間が必要で、様々な課題があります。一方、自然界に見られるアプローチは、柔軟性や適応性を持ちます。例えば、蟻は一つ一つは大した知能を持たなくても、協力して橋を作り、谷を越えることもある。これは、1つ1つは非常に少ないリソースでも、大きな成果を達成できる可能性を示しています。
今回紹介するモデルマージは2つ以上の機械学習モデルをもとに1つの新しいモデルを作るという技術で、大きく2つのアプローチがあります。1つ目は重みレベルのモデルマージです。これは2つのモデルの平均を取るような形で、新しいモデルを生成する方法です。簡単な手法ですが、結構うまくいきます。
二つ目はレイヤーレベルのモデルマージです。こちらはモデルの重みを変更せずに、異なるモデルのレイヤーを重ね合わせる手法です。このアプローチでは、パラメータの数が減ったり増えたりするという特徴があります。
これによって、1つ1つのモデルの予測結果よりも性能が良くなったり、複数のモデルの持つ能力を統合したりすることができるようになると考えられています(図表5)。
このモデルマージというのは英語圏ではかなり話題になっていたのですが、日本のAIコミュニティではそれに比べて話題になっていませんでした。これには日本語ベースモデルの特徴が関係していると考えていまして、まず日本にはプレイヤーが少なく、マージできるようなオープンソースのモデルというのが少ない点。もう1つは、技術的な理由により、日本語のLLMと英語のLLMではマージがうまくいかないという点。しかし、むしろこれはチャンスだと私は捉え、進化的モデルマージという技術を開発しました。
進化的モデルマージは、先ほどの2つのアプローチを組み合わせ、進化計算と呼ばれるアプローチによってより複雑な新しいモデルを作るための技術です。アルゴリズムの詳細はスライドに記載のブログなどを見てもらえればと思いますが、かなり汎用性があり、いろいろなものを最適化することができます。
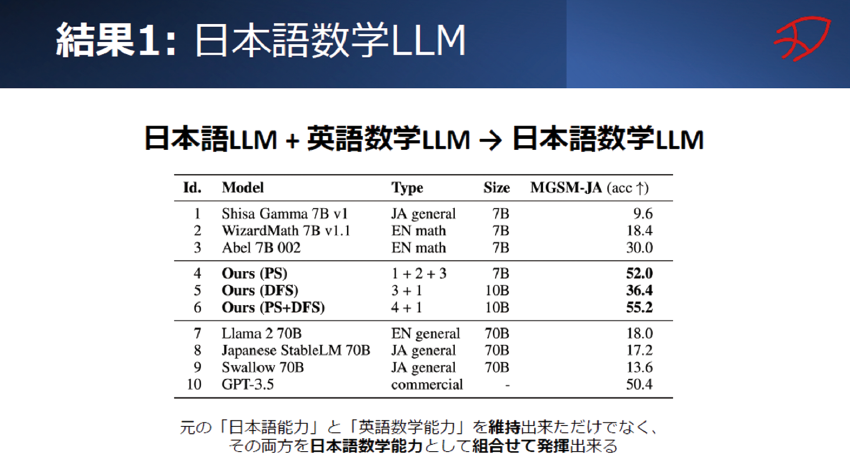
我々はこれを使って、非常に柔軟かつ適応的な新しいモデルの作り方を開発しました。その実証実験の結果の一つですが、日本語の言語モデルと英語の数学特化モデルを混ぜ合わせ、日本語で数学問題を解けるモデルを開発しました。元の日本語モデルは数学の能力が足りず、英語モデルは日本語が分からないのですが、2つを混ぜ合わせることで新しい能力を発現することに成功したわけです(図表6)。
さらに、日本語の言語モデルと英語のビジョン言語モデルを組み合わせ、日本語対応のビジョン言語モデルを作成することにも成功しました。進化的モデルマージが単なる性能向上ではなく、今までできなかったことをできるようにする、非常に新しい技術であると考えております。

<講演資料掲載ページ>
https://www.nistep.go.jp/archives/57541

※ 本記事内図表はすべて講演者の使用スライドより許可を得て掲載。
