
- PDF:PDF版をダウンロード
- DOI: https://doi.org/10.15108/stih.00269
- 公開日: 2021.11.25
- 著者: 齊藤 美智子、蒲生 秀典
- 雑誌情報: STI Horizon, Vol.7, No.4
- 発行者: 文部科学省科学技術・学術政策研究所 (NISTEP)
ナイスステップな研究者から見た変化の新潮流
国立研究開発法人物質・材料研究機構
統合型材料開発・情報基盤部門
主任研究員 桂 ゆかり 氏インタビュー
-論文から過去の実験データを集めることで
大規模材料物性データベースを構築-
科学技術予測・政策基盤調査研究センター 特別研究員 蒲生 秀典
「ナイスステップな研究者2020」に選定された桂ゆかり氏は、高校時代をオーストラリアで過ごし、帰国後は東京大学応用化学科に進学。合成系の研究室に所属しながら、第一原理計算に興味を持ち、解析に着手、本格的にデータ科学の道へ。論文中のグラフから収集した実験データを集めた世界初のデータベースStarrydata(「スタリ―データ」)注2を開発し、広く一般に公開。熱電材料において論文データをもとにしたデータベース作成プロジェクトを運営し、構造・物性のデータベースを構築し、新規材料探索・材料開発の加速につながる研究基盤構築に先駆的な貢献をした。加えて、所属する日本熱電学会において熱電特性のデータベース化プロジェクトを推進し、広く全国各地の大学や研究機関での説明会などを行い、協力が得られた研究者や学生をメンバーとしたプロジェクトチームを運営し、熱電材料の構造・物性データベースを構築した。また、Starrydata2の開発後、研究室で生まれた実験データを管理するデータベースStarrydata3の開発にも取り組んでいる。
今回のインタビューではStarrydata開発のきっかけや、海外での高校生活や自身の研究内容、実験データのデータベース化について、また、今後の研究の展望について伺うとともに、研究者を目指す方々に向けてメッセージを頂いた。

桂 ゆかり 氏(桂氏提供)
- 先生の御研究やオープンデータベースStarrydataの開発についてお聞かせください。
論文からの実験データの収集とデータベース化
過去の実験データを論文から集めて、データベース化する研究を行っています。研究者は数多くの論文を読んでいますが、読める論文の数は限られています。自分の研究分野でどんな論文が出ていて、どんな傾向になっているのか全て見通すことはできません。それをデータに基づいてまとめているのがStarrydataという私たちのデータベースです。
データを集めると、研究の世界が変わります。実験系の研究者は、傾向に基づいてこのへんが良さそうだ、このへんはやっても駄目なんだという情報がわかって、効率的に研究ができます。計算系の研究者は、計算結果が実験データと合っているかどうか見比べながら、より正確な計算を目指すことができます。
データ収集システムの構築
最近流行りの機械学習などのデータ科学を使ったマテリアルズ・インフォマティクスという研究にも、膨大なデータが必要です。そこで、私たちが実験データを大量に集めることで、実験データの機械学習をできるようにします。
実験データを論文のグラフから読み取る作業は、自動化したら楽だという方も多いのですが、手作業の方がいいです。自動化できるのはデータ収集作業のうちのほんの一部、数十秒で終わるグラフトレース部分です。それ以外の「データを説明する」という作業は自動ではできないので、きちんと人が論文を読むことが必要になります。
論文を集めていると色んなグラフが出てきます。グラフの縦軸・横軸の物理量も、数値の桁の表示方法も、単位の表示の仕方も様々なので、それを全部理解しないと正しくデータを収録できません。解釈をひとつでも間違えると、データに外れ値が混ざります。データ解析をやっていて一番面倒なのが、桁の違う外れ値が混ざることです。それからグラフから数値データを抽出する作業でも、手作業の方が、多様なグラフに対応できる手応えを感じます。数値を取り出した後は、データの説明を書きます。論文を読んで、試料の化学組成や製法、測定方法を推理しながら書き込みます。手作業でのデータ収集をアシスト(機械化)できる部分は、膨大なデータ管理や整理の補助作業です。
2015年当時、東京大学の助教だった私が、日本熱電学会での知り合いで、大阪大学の博士課程の学生だった熊谷将也さんに声をかけて、Starrydata webシステムの開発を始めました。熊谷さんは高専で情報科学を学んだあとに大学で材料科学を学んでおり、web開発と無機材料合成の両方を理解している稀有な存在でした。2016年にStarrydataの最初のバージョンを作った後、2017年にその改善版のStarrydata2を作りました。熊谷さんと一緒に、熱電学会の研究者や学生を巻き込んでデータ収集を行おうと試みてきました。そんな私たちの研究が認められ始めたのが2019年で、論文がアクセプトされ、国際学会や国内学会で賞を頂きました。2020年以降は、材料科学研究を支援する色んなwebツールを集めたE4M(Elements for Materials)というサイトを立ち上げたり、電子ラボノートを開発したりと、活動の幅を広げています。
オープンデータベースとして公開
Starrydataは無償のオープンデータベースとして作成しています。オープンデータベースと言うと、作った人が損するボランティア活動のように考える人もいますが、オープンデータベースにすることでコスト面でのメリットがあります。仮にオープンデータベースにせずに、ユーザーからお金を取ると、データを盗まれないためのセキュリティ周りの開発費がかさみます。また、サービスが良くないと不満が出るので、開発のハードルが上がってしまいます。さらに、商用利用を行うことで、出版社から論文を購入する必要が生じてしまいます。Starrydataは完全にオープンなアカデミックな活動として進めていくことで成功できたのです。なお、論文から実験データを集めることは著作権侵害ではありません。著作権というのは創作物、表現物に係るものなので、文章やグラフのデザインは著作権による保護対象ですが、客観的事実であるデータは保護対象ではありません。そのため自由にシェアすることができます。必ず引用元を示すという科学のルールを守ることで、フェアな形で実験データを共有できます。
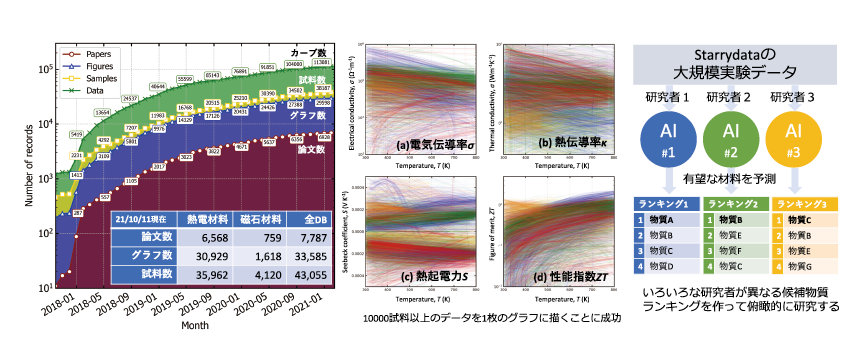
Starrydataに登録された論文は7800本、データが登録されている試料は4万個ぐらいです。1試料あたり複数の測定結果が掲載されているので、収録カーブ数で言うと約12万あります(図表(a))。
機械学習による熱電材料の探索
Starrydata活用の一環として、熱電材料のデータベースをプロトタイプとして作成しました。様々な熱電材料のデータを集めたところ、材料の種類によってばらつきはあるものの、特性の分布が束になって現れるという特徴を見ることができました。これをできたのは今回のデータベースが初めてです(図表(b))。今回集めたデータを機械学習させることで有望物質のランキングを作ってみたのですが、機械学習のプログラムによって違うランキングになりました。機械学習は厳密な物理の理論ではないので、ひとつの答えが出るのではなく、アルゴリズムや設定によって全く異なる結果が出ます。その中で優秀な機械学習プログラムの場合は出てきたランキングが多くの良い材料を含むものになります。このため、機械学習プログラムを独自のものに設計するという研究にもなるし、良いプログラムができたらみんなで共有する、それに基づいて研究するという新しい研究分野になるだろうと思っています(図表(c))。
企業との共同研究への発展と世界への発信
Starrydataの研究を紹介すると、企業から新しいデータベースを作りたいというお話を頂くことがあります。効率の良い論文データ収集ができそうだとわかれば、共同研究という形で研究費を頂いてデータ収集をしています。研究費はデータ収集者を増やすための人件費として使います。私たちはアカデミックな活動の一環としてデータを集めるので、データはその企業が独占するのではなく全世界に公開されますが、それでもデータを使ってみたい企業から声をかけていただいています。
- これまでの先生の研究分野について移り変わりとそのときの思いやお考えを教えてください。
東京大学2年生のときに応用化学科に進んだのは、やれることが多そうだと思ったからです。元素が好きだし、材料研究だと応用的なものも基礎的なものもあるし、自分の手に取って色んなものを作れるし、楽しそうだと思って選びました。
研究室を選ぶときも、色んな実験ができそうな合成系の研究室にしました。ただ粉だけ混ぜて試料ができても、原子の世界で何が起こっているのかが見えないと、つまらない気がしました。このため博士課程1年のときに、自分の研究費でソフトを買って第一原理計算と呼ばれる物性シミュレーション計算を独学で始めました。当時は実験と計算の両方をする研究者は余りいませんでした。計算に軸足を移したもう一つの理由は、将来子育てをするときのためでした。産休や育休を取ったときにも、家で研究を進められて便利でした。ポスドクの頃は、プログラミングで数多くの計算を回す研究を始めました。これは後に「ハイスループット計算」という呼び名ができて、マテリアルズ・インフォマティクスの骨格を支える技術になりました。
2015年に物質・材料研究機構(NIMS)でMI2I(情報統合型物質・材料開発イニシアティブ)が立ち上がった際に、その初期メンバーとして声を掛けていただきました。このとき初めてデータ科学やデータベースの勉強をしたのですが、その中でまだ誰も試していない面白いことがないかと考えたとき、論文から実験データを集めたらどうだろうと思って、構想を膨らませていきました。わからないことだらけなので、データ科学やデータベースに詳しそうな先生たちに連絡を取って話を聞きに行きました。こうして実験・計算・データ科学と研究分野を変えてきたことで、いろいろな分野の視点を持つことができたのが、今のプロジェクト設計に役立っています。
- 研究での御苦労や苦心される点があればお聞かせください。
今、研究していて大変なのは、データ収集のチームを維持することです。このプロジェクトには人件費が必要ですので、研究費を獲得する努力と、予算を使う事務手続に多大な時間が取られます。多くのプロジェクトを抱えると、内容を切り分けてつじつまを合わせる作業も増えて、研究の本質ではないことに振り回されやすくなります。
「選択と集中」の名のもとに一部の研究者に大きな研究費を集中投下する現在の体制では、不採択にされる多数の研究者も、採択される少数の研究者も、審査側の研究者も多くの時間を奪われています。そして、研究そのものに割ける時間がほとんどなくなってしまいます。採択されるために成果を誇張する研究者が増えてしまうことで、科学に真摯な研究者が研究を続けられなくなる可能性もあります。
そんな中で生き残るには、自分が研究者として世界のために何ができるか、強い信念を持って計画を立てることです。自分の中でつじつまが合うまで一生懸命考えて、組み上がった論理を信じて壮大なプロジェクトを計画すると、その価値に気づいてくれる優秀な人たちが集まってくれます。科学に真摯な人は、新しく置かれた状況でも正解にたどり着く力を持っています。そんな人たちが集まったチームは居心地が良く、互いの能力を伸ばし合える環境となります。
- 海外での高校生活が、どのように影響しているとお考えになりますか。
海外生活経験のある人に共通していると思うのは、「これはこうしなければいけない」という常識にとらわれず、「結果が正しければ、違うプロセスでも構わない」という柔軟性を持っていることです。日本の中学を卒業後、オーストラリアの中高一貫女子校の9年生に編入したのですが、現地の人が信じている常識に対し、日本人として「違う」とツッコミを入れたくなるときが多くありました。反対に日本で常識だと思っていたことが、現地ではそうしなくてもうまくいっていることを見て、自分を縛る常識が減っていきました。
異文化でマイノリティとして暮らしたことで、人の考え方の多様性を感じることができました。日本で研究者をしていても、研究分野をまたぐのは異文化体験です。違う研究分野の考え方を理解して、その人たちに伝わるプレゼンや文章を考える能力も鍛えられたのではないかと思います。
また、その学校の校風なのかオーストラリアの国民性なのか、人の成功をねたむのではなく、心から喜んでくれる人たちに囲まれました。日本では褒められるに値しないことでもすごく良いと褒めてくれて、私が活躍することを喜んでくれる人たちが数多くいました。これによって、今まで持てなかった自分への自信を持てるようになりました。
それからもちろん、英語ですね。高校生活だけでは全然ネイティブにはなれませんでしたが、研究開始時点で英語がわかる状態だったことはアドバンテージになりました。論文を読むのが速かったり、高校で習ったライティング技術が論文を書くのに使えたり、国際学会での発表も余裕でできたり、外国の研究者の話が聞き取れるので良かったです。ただ英語は研究者生活でずっと使い続けるものなので、ほかの日本人研究者も年齢が上がるほど英語が上手になりますし、私も帰国直後より今の方が英語を上手にしゃべれると思います。
- 今後の研究の展望について教えてください。
材料科学はもっと俯瞰的に、もっと効率的にできると思っています。最近DX(デジタルトランスフォーメーション)という言葉が使われておりますが、材料科学にもDXを起こしていきたいです。Starrydataの共同開発者の熊谷さんと最近取り組んでいるのは、材料科学のちょっとした計算を自動化したミニアプリを集めた、E4Mというサイトの立ち上げです。面倒な作業に費やす時間を減らし、本質を考えることに時間を注いでもらうことで、世界全体から材料研究の成果がどんどん出てくるようにしたいです。
論文からデータを集める活動を熱電材料以外の材料に広げていって、マテリアルズ・インフォマティクスに使える公共のデータを増やしたいです。それには、チームを大きくしていくことが必要です。アメリカなど諸外国の大きなAI研究では、データを手作業で集める必要性が理解されています。キュレーター(データ収集者)が何百人、何千人もいて、データを組織的に集めて機械学習しています。キュレーターによる論文からの材料データ収集に関しては、幸い私たちのチームが世界をリードできている状況にあるので、今のうちに大きなチームに成長させて、「論文データ収集は日本の得意分野」となれるようにしていきたいです。
- 研究者を目指す方々へのアドバイスをお願いします。
研究者は何でも屋みたいな仕事です。色んな技術を身に着けて、色んな場所に行って、たくさんの人と出会って、有名人だろうと地位の高い人でも、誰でもいいので気の合う人をどんどん仲間にして世界を動かす仕事なので、楽しいです。
また、博士号を取っても意味がないと思う人が多いようですが、国の研究費に応募できる切符のようなものです。研究費は人のために役に立つプロジェクトのための予算です。国の予算で採算度外視のベンチャーのような仕事ができます。もうけなどにとらわれずに良いことをしたい、気の合う人たちとつながって大きなことをしてみたい人にとっては、魅力的だと思います。
また、私としては、「こんなものは研究として認められないだろう」と思う研究テーマを進めてみることもおすすめします。それが新しい研究分野になるからです。自分の中で論理を組み上げたときに、そこに新しい研究が必要だったら、それをテーマとして立ち上げるのです。私は「他人の論文のデータを集めるなんて研究とは言えない」というところからのプロジェクトでした。どう考えてもその研究が必要なのだと、自分の中で論理ができたなら、それは信じる価値があります。広い世界から、優秀な気の合う仲間たちを見つけてきて、一緒にその分野を開拓していってほしいと思います。
(2021年9月6日オンラインインタビュー)
注 Starrydata(スタリ―データ):https://starrydata.org/
