
- PDF:PDF版をダウンロード
- DOI: https://doi.org/10.15108/stih.00363
- 公開日: 2024.03.21
- 著者: 鎌田 久美
- 雑誌情報: STI Horizon, Vol.10, No.1
- 発行者: 文部科学省科学技術・学術政策研究所 (NISTEP)
ほらいずん
海外技術情報
「コンピュータビジョンとパターン認識に関する
国際会議2023 CVPR2023」参加報告
-コンピュータビジョンと人工知能分野のトップカンファレンス-
「コンピュータビジョンとパターン認識に関する国際会議2023(CVPR2023)」は、2023年6月18日から22日まで、カナダのバンクーバーで開催された。
CVPRはコンピュータビジョンと人工知能分野で採択率が約25%前後の最難関の国際会議であり、当該分野の最先端の研究が発表された。発表内容は、マルチビューの3次元(3D)構成画像に関する研究、機械学習を用いた画像・動画の生成に関する研究、人の顔やポーズの画像に関する研究等の発表が実施された。
今回の投稿数は9155件、採択数は2359件、採択率は25.8%であった。国別の参加者数は、第1位が米国の2779件、第2位が中国の1413件、第3位が韓国の815件、第4位がカナダの672件、第5位がドイツの372件、第6位が日本の304件であった。
コロナ禍以来、2020年から2021年まではバーチャル開催であったが、2022年以降はハイブリッド開催となり、現地参加者が戻りつつあり、研究者同士が対面で会って議論することが再び増えた国際会議となった。
キーワード:コンピュータビジョン,ジェネレーティブAI,3D構成画像,自動運転
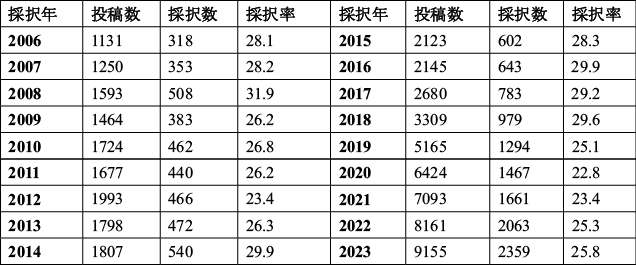
1. 投稿数と採択数の推移(2006-2023)
CVPRの投稿数、採択数及び採択率の推移が発表された。
CVPR2023の投稿数(全体)は9155件、採択数は2359件、採択率は25.8%となっている。投稿数は2017年以降急激に増加しており、採択数も同様に増加している。採択率は約25%~30%であり、CVPRはコンピュータビジョン分野のトップカンファレンスであり、最難関とされている(図表1)。
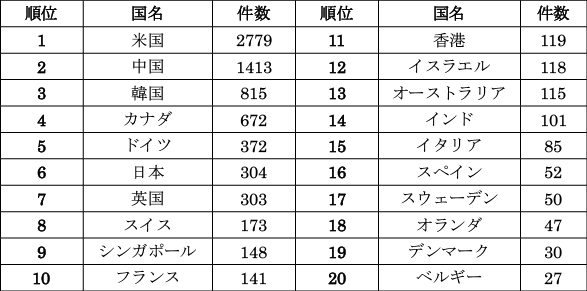
2. CVPR2023の国・地域別の参加者数の内訳
CVPR2023の国別の参加者数の内訳が発表された(図表2)。
第1位は米国の2779件、第2位は中国の1413件、第3位は韓国の815件、第4位はカナダの672件、第5位はドイツの372件、第6位は日本の304件等となっている。米国と中国の参加者が多数を占めていた。
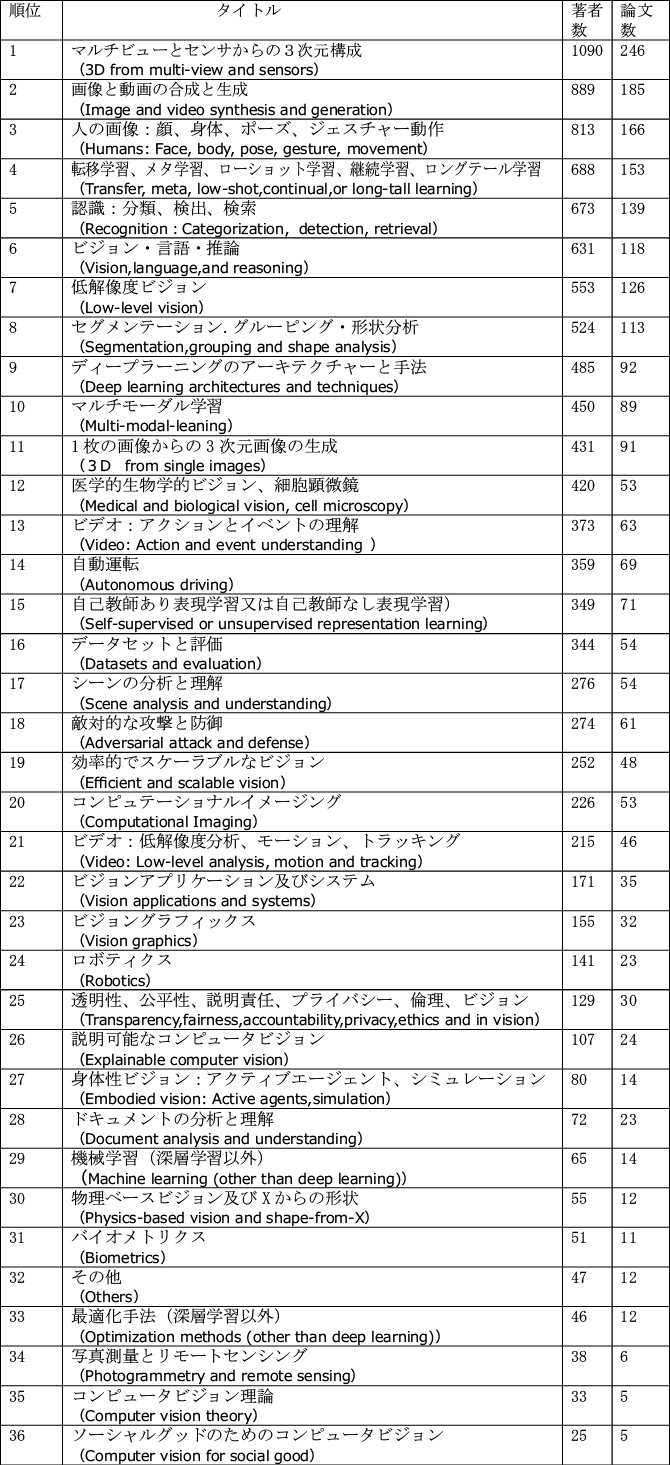
3. CVPR2023の分野別の発表件数
CVPR2023の分野別の発表件数(著者数による順位)が発表された(図表3)。
第1位の「マルチビューとセンサからの3次元構成」は、マルチビュー(多視点)を利用して、対象物を複数の画像からとらえて3次元構成画像を生成する研究であり、著者数が1090名、論文数が246件と最も発表が多かった。
第2位の「画像と動画の合成と生成」は、Stable Diffusion(ステイブル・ディフュージョン)などの深層学習を用いた画像と動画の生成に関する研究が多数発表されており、著者数889名、論文数が185件と多くを占めていた。
第3位の「人の画像」に関する研究は、顔、身体、ポーズ、ジェスチャー動作等の立体画像を基にした、様々な表情や動作の創出に関する研究、人のポーズやジェスチャー動作の表現に関する研究が発表されており、著者数813名、論文数166件であった。
4. 受賞論文
CVPR2023の論文受賞は、最優秀論文が2本、佳作(優秀)論文が1本、学生最優秀論文が1本、学生佳作(優秀)論文が1本であった。
①最優秀論文-1
「Visual Programming(VISPROG); Compositional Visual Reasoning Without Training:(ビジュアルプログラミング:訓練なしの構成的視覚的推論)」1)
Tanmay Gupta氏、Aniruddha Kembhavi氏(Allen Institute for AI)(米国)(図表4)
この発表では、自然言語の指示を受けて、複雑で構成的な視覚的タスクを解決することが可能な、ビジュアルプログラミング(VISPROG)を提案している。1枚又は複数画像と自然言語の命令を与えて、GPT-3を利用して命令プログラムを生成し、そのプログラムを実行することで目的の出力を得るシステムとなっている。GPT-3によってタスク固有の訓練が不要となり、少数の例からプログラムを作成できること、中間出力を確認することで間違いの理由や視覚的根拠を得ることが特徴となっている。
ビジュアルプログラミングは、大規模言語モデルのコンテキスト内学習機能を使用して、モジュール型プログラムを生成し、コンピュータビジョンモデル、画像処理サブルーチン、又はPython関数を呼び出して、中間出力を生成する。これらの作業によって、解釈可能な理論的根拠と解決策を得ることを実現している。そして、視覚的質問への構成的な回答、画像ペアのゼロショット推論、事実知識オブジェクトのタグ付け、及び言語ガイド付き画像編集の4つのタスクにより、一連の作業の柔軟性を実証している。
今回紹介された、Neuro-Symbolic AI(ニューロシンボリックAI)注1によるアプローチに基づくビジュアルプログラミングは、AIシステムを簡単及び効果的に拡張して、利用者が実行したいと考えている複雑なタスクに対応ができる、非常に有用なシステムであると紹介されている。

②最優秀論文-2
「Planning-oriented Autonomous Driving:(計画的自動運転)」2)
Yihan Hu氏、Jiazhi Yang氏、Li Chen氏、ほか
(Shanghai AI Laboratory, Wuhan University, Sense Time Research)(中国)(図表5)
自動運転は非常に複雑な技術から構成されていて、モジュール化(単体で特定の機能を発揮することができる単位)したタスクである認識、予測、計画を順番に実行することが特徴であるが、これまではフレームワーク(枠組み)に関する研究は余り行われてこなかった。
自動運転の実現には、エラーや調整不足の発生に備えて、有利なフレームワークを考案し最適化すること、認識と予測の主要素を再検討し、全てのタスクが自動運転の計画に貢献するようにタスクに優先順位をつけることが必要となる。最近のアプローチは、高度なインテリジェンスを持つスタンドアロンモデル(機器やシステムが外部に接続、又は、依存せず単独で機能している状態のこと)、及びマルチタスクパラダイム(システムが同時に複数のタスクを平行して実行するという理論的な枠組み)を設計することが挙げられる。
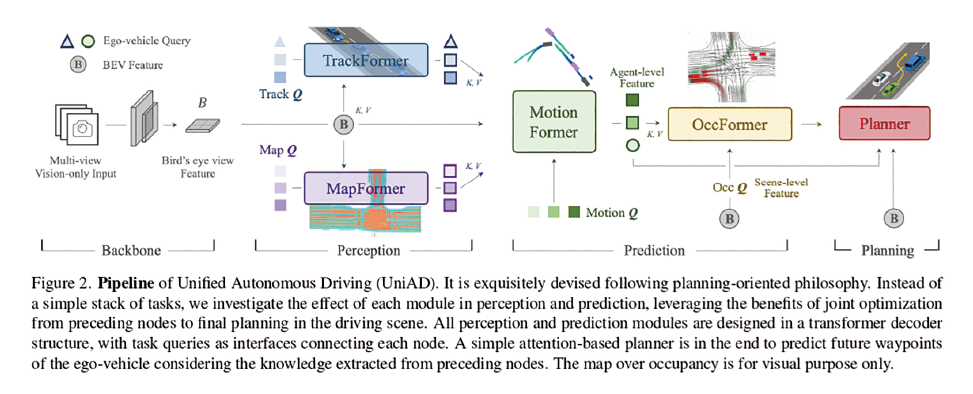
今回の論文では、統合自動運転Unified Autonomous Driving(UniAD)が提案された。これは、認識タスクにおける物体の検出、追跡、走路のマッピング、予測タスクにおける行動予測や占有状態予測など、フルスタックの運転タスクを1つのネットワークに組み込んだ、最新の包括的なフレームワークである注2。このフレームワークによる革新的なアプローチは、自動運転技術研究における重要なブレークスルーとなり、受賞となった。
③佳作(優秀)論文
「DynlBaR: Neural Dynamic Image-Based Rendering:(ニューラルダイナミックイメージベースレンダリング)」
Zhengqi Li氏、Qianqian Wang氏、Forrester Cole氏、ほか
(Google Research, Cornell Tech)(米国)
単眼カメラで撮影された動画から、全く別の視点から見たときの映像を違和感なく再構成する。動きの激しい物体でも消えたりボケたりすることなく、任意視点でシーンを再構成できている。
④学生最優秀論文
「3D Registration with Maximal Cliques:(最大限排他的3次元レジストレーション)」
Xiyu Zhang氏、Jiaqi Yang氏、Shikun Zhang氏、ほか
(Northwestern Polytechnical University)(中国)
コンピュータビジョンで課題となっている、3次元点群処理における点群ペアをそろえるための最適手法として、3次元レジストレーション法とディープラーニング手法を組み合わせることで、性能が向上されたことが示された。
⑤学生佳作(優秀)論文
「DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation(被写体とテキストからのイメージのディフュージョンモデル)」
Nataniel Ruiz氏、Yuanzhen Li氏、Varun Jampani氏、ほか
(Google Research, Boston University)(米国)
異なるテキスト入力に従って、被写体の特徴を多く残しつつ、様々な状況やシーンでの被写体が含まれる画像を生成する研究が発表された。
5. 企業展示
国際会議への出展は、学界や産業界の世界的リーダーに宣伝するための最も費用効果の高い方法であり、業界のパイオニアとのつながり、ターゲットとする潜在的な顧客を獲得する機会となる。又、優秀な学生をリクルートする絶好の機会となっている(図表6)。


6. 招待講演
CVPR2023の招待講演の中で注目を浴びていた講演を紹介する。
基調講演「Recycling Old Vision Ideas in a Modern Computational World」
Rodney Brook氏(MIT)3)
マサチューセッツ工科大学のロドニーブルック氏による「現代のコンピューティング世界における、古典ビジョンのアイデアのリサイクル」と題する発表があった。「アイデアは何度も繰り返しやって来て、時々より良い結果をもたらす。最新世代のニューラルネットワークは、新しいシリコンのアーキテクチャーをもたらした。」と述べ、アイデアの温故知新の必要性について指摘した。
また、コンピュータの急速な進化について、「1900年から進化を続けて、1000ドルのコンピュータは、2000年には昆虫の頭脳に匹敵するようになり、2020年には一人の人間の頭脳に近づき、2045年には全人類の頭脳に匹敵するようになる(シンギュラリティ)。」と述べた。
7. まとめ
対面を中心として開催された国際会議であったため、活気が戻ってきた雰囲気であった。大会当局も、ポスターセッションや展示会等に重点をおいた構成にして、対話を重視したプログラム構成となっていた。
コンピュータビジョンの研究内容は、基礎研究から応用研究まで発表されていたが、自動運転やロボット、3D動画像などの研究が多数発表されていた。生成AIを用いた画像編集の研究が発表されて注目を浴びていた。
日本の発表も貢献しており、参加者数も第6位と多く、この分野の関心が大きいことが示されていた。
注1 Neuro-Symbolic AI(Neuro=ニューラルネットワーク、Symbolic=記号的表現に基づく):深層ニューラルネットワークの強み、及びシンボリック(記号的表現に基づく)AIの強みを合わせ持ったAIのことを指す。IBMなどが中心となって進めている最新のAI技術である。
注2 大規模なアブレーション(機械学習の予測モデルにおいて構成要素の一部分を取り除いて実験を行い、結果を比較すること)では、これまでの最先端技術を大幅に上回るパフォーマンスを示している。
